

Hvordan virker billedgenkendelse?
De seneste årtier er der blevet forsket meget i at få computere til at forstå billeder, da det især skaber store muligheder inden for eksempelvis diagnosticering af sygdomme og selvkørende biler. Den førende teknologi bag billedgenkendelse er inspireret af den måde vores hjerne bearbejder synsinput og hedder Convolutional Neural Network (CNN).
Teknologien bag CNN beskrives dybdegående i denne artikel. Det forklares, hvordan et convolutional neural network er opbygget, sådan at det kan klassificere billeder. Dette gøres grundlæggende i tre forskellige lag. Først detekteres karakteristika ved et objekt i et convolutional layer, hvorefter disse karakteristika komprimeres i et pooling lag. Disse to processer gentages for at opnå et større abstraktionsniveau i netværket. Til sidst bruges et fully connected layer til at klassificere billedet ved at vægte sammenhængen mellem de detekterede features. En af de helt centrale fordele ved et neuralt netværk er at identificere features selv.
Her beskrives to centrale algoritmer i læringsprocessen: gradient descent samt backpropagation. Googles netværk GoogLeNet Inception_v4 er nu så godt, at de har en fejlidentificeringsprocent på 3,1%, hvilket er bedre end mennesker. På trods af disse resultater, har vi ikke set en stor brug i sikkerhedskritiske systemer som sundhedsvæsenet endnu.
Convolutional Neural Network
Convolutional Neural Network (CNN) er en deep learning algoritme, til billedgenkendelse, inspireret af den måde, vi bearbejder synsinput. Vores hjerne fungerer ved at finde “features”, som kategoriserer de objekter vi ser. En feature er en karakteristika ved et objekt. Vi bearbejder vores synsinput og de forskellige features i lag. I første lag vil vores hjerne søge efter simple former som linjer og kanter. I de efterfølgende lag vil formerne blive mere og mere komplekse, da hjernen kombinerer de forskellige features, så vi til sidst kan identificere objekter.
CNN fungerer meget på samme måde. Ved at reducere billederne i en form, der er nemmere at behandle, uden at miste information om de features der er nødvendige for at identificere objektet på billedet. Herefter vægtes forskelligekarakteristika mod hinanden i stedet for at kigge på hele billedet.
I forbindelse med billedgenkendelse, så består CNN’er af 3 forskellige elementer. De to første går igen for alle CNN’s og består af: convolutional layer og pooling layer. Disse kan kombineres på forskellige måder og gentages afhængig af hvordan netværket designes. Det sidste element er afhængig af, om netværket skal udføre en classification, segmentation, object detection eller image captioning. I en classification vil det sidste element bestå af en fase kaldet fully connected layer.

Convolutional Layer
Convolutional layer har til formål at identificere og tydeliggøre features, i billedet og fjerne de features den vurderer som irrelevante.
Der er tre elementer, der bliver brugt i denne operation: Input billedet, en feature detector/filter og et feature map.
Input billede
Når maskinen til billedgenkendelse modtager et input billede, kan den ikke se billedet, som vi mennesker gør det med pixels i forskellige farver. I stedet ser maskinen en matrix af værdier, hvor hvert felt er en pixel. Værdierne repræsenterer de forskellige koncentrationsniveauer i farver mellem 0 og 255. I et sort/hvid billede vil værdien 0 repræsentere sort mens 255 vil være hvid og alt imellem vil være nuancer af grå. Et farvet billede vil blive læst i en matrix i 3D, hvor dybden vil være 3, da der både er værdier for rød, grøn og blå.
Feature detector
Feature detector er en mindre matrix (f.eks. 3×3 pixel) bestående af værdier der leder efter features i billedet såsom kanter og streger, som den har lært at den skal finde for at identificere et specifikt objekt. En feature detector analyserer ét område af gangen og starter med at lede oppe i venstre hjørne af billedet. Matrixens værdier ganges med værdierne i input billedet og bliver lagt sammen til en enkelt værdi der bliver lagt over i feature mappet.
Herefter bevæger feature detectoren sig mod højre til den når højre kant og gør det samme igen nedenfor. Denne proces fortsætter indtil hele billedet er analyseret for den pågældende feature og et færdigt feature map er klart.
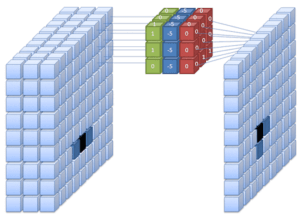
Feature map
For hver feature detector der bruges, vil der blive lavet et feature map, hvor den feature der ledes efter vil være tydeliggjort. Convolutional layer kan bruges flere gange i samme CNN. Ofte kombineret med flere Pooling Layer’s. Det første convolutional layer vil kigge efter er low level features, såsom streger og kanter, mens de efterfølgende convolutional layer’s vil kigge efter medium og high level features, som er mere komplekse mønstre. I dag findes der netværk med over 150 lag.
Aktiveringsfunktion
I CNN bruges der, ligesom i andre neurale netværk, en aktiveringsfunktion til at gøre output ikke-lineært. Rectified Linear Unit også kaldet ReLU er den mest brugte aktiveringsfunktion i deep learning. Funktionen gør at output bliver 0, hvis input er negativt mens, hvis input er positiv, er output den samme værdi som input. Dette er nødvendigt da dataen i billedgendkendelse er meget kompleks, og læring i netværket ville være umuligt uden.
Pooling Layer
Formålet med pooling er at reducere antallet af pixels i billedet, så beregningskompleksiteten mindskes.
Der findes flere forskellige typer af pooling, hvoraf de mest brugte er max pooling. Pooling fungerer ved, at maskinen kører en mindre matrix over billedet, og samler de pixels, der er i matrixen til en enkelt værdi/pixel. Når man bruger max pooling, er det kun den højeste værdi, der får lov at blive tilbage. Pooling operationen fjerner en masse irrelevant information i billedet. Efter reduceringen kan netværket gøre sit job mere effektivt. Output billedet kaldes Pooled Feature Map.
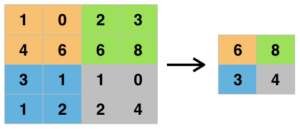
Fully Connected Layer
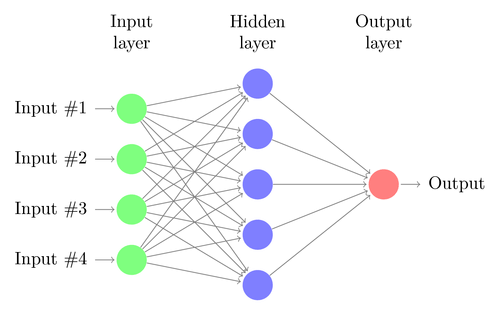
Efter at input billedet har været igennem det ønskede antal af convolutional operations og poolinger, skal billedet tilpasses, så det kan bruges som inputlag til et fuldt forbundet neuralt netværk. Dermed bliver samtlige pixels fra samtlige pooled feature maps “fladet ud” til en vektor i 1D, og værdien for hver pixel bliver til en input neuron i et fuldt forbundet neuralt netværk. Nu skal netværket forudsige sandsynligheden for, at billedet tilhører de forskellige kategorier, den kigger efter.
I fully connection fasen bliver alt forbundet i et fuldt forbundet neuralt netværk i modsætning til de forrige faser, hvor netværket har været lokalt forbundet og kun bearbejdet et lokalt område ad gangen. Det betyder at hver neuron er forbundet til samtlige kunstige neuroner i forrige lag. Dermed tager netværket alle de tidligere identificerede features og vægter dem mod de forskellige mulige outputs. Værdien i output laget bliver derefter kørt igennem en aktiveringsfunktion kaldet SoftMax. Denne funktion gør at værdierne vil ligge i intervallet 0 til 1. Hver værdi er forbundet med et objekt (fx. en kat, en bil, en blomst). Jo tættere på 1 et objekt har, desto mere tror netværket at den har fundet et match mellem input billedet og denne.
Machine Learning i Convolutional Neural Network
Før et CNN kan fungere, skal det trænes. Det er her machine learning kommer ind i billedet. Antallet af convolutional layers, pooling layers samt dybden af det fully connected layer er alt sammen noget som arkitekten bag netværket har bestemt, mens at filtre, vægte og bias er noget netværket lærer sig selv. Som tidligere forklaret er de forskellige objekter, som netværket skal genkende, repræsenteret af en neuron med en værdi mellem 0 og 1 i output laget. Jo tættere på 1, desto mere sikker er netværket på, at den har fundet et match. I et veltrænet netværk vil den rigtige klassificering ligge på omkring 1, mens de andre klasser vil være tæt på 0. I et ikke trænet netværk vil værdierne ligge spredt.
I et utrænet netværk bruger man funktionen cost function til at vurdere hvor godt eller dårligt netværket præsterer. Den beregner hvor langt de forkerte objekters værdi ligger fra 0 og hvor langt det rigtige objekt ligger fra 1. Den centrale algoritme til at træne et CNN hedder backpropagation. Backpropagation algoritmen finder de vægte og biases, som har størst betydning for at ændre netværkets output mod det rigtige. For at optimere disse, bruger man en anden algoritme der hedder gradient descent. Denne finder cost funktionens minimum ved at justere de vægte og biases der er identificeret gennem backpropagation.
Hver gang informationer bevæger sig frem i netværket bliver input ganget med en vægt og et bias bliver tilføjet. Det er denne vægt og bias som netværket lærer at tilpasse. Hver gang netværket får et nyt billede, og bliver fortalt, hvad der er på billedet, vil netværket tilpasse sine vægte og dermed blive bedre og bedre til at genkende kategorien. Dataen netværket fodres med, bruges derfor til at minimere fejl i output.
Teknologiens historie
1959: Neurofysiologerne David Hubel og Torsten Wiesel kortlægger hjernens tolkning af synsimpulser fra nethinden. Ved at placere elektroder på en kats visuelle cortex, observerede de neuronernes aktivitet, når de viste katten forskellige billeder. Forsøgene viste at vores visuelle cortex behandler synsinput i hierarkiske lag.
1980: Baseret på David Hubel og Torsten Wiesel’s opdagelser i 1959, udvikler den japanske datamatiker Kunihiko Fukushima et kunstigt neuralt netværk ved navn Neocogniton. Netværket kunne genkende mønstre i forskellige positioner.
1986: Geoffrey Hinton beskriver en ny læringsprocedure for neurale netværk kaldet backpropagation.
1998: Den franske forsker Yann Lecun tager Fukushimas Neocogniton og anvender backpropagation. Netværket bliver opkaldt LeNet-5.
2012: Alex Krizhevsky vinder ImageNet konkurrencen med sit Convolutional Neural Netværk AlexNet. Det er første gang et Convolutional Neural Network vinder konkurrencen siden den startede i 2010. I konkurrencen skal algoritmer klassificere 150.000 forskellige billeder i 1000 forskellige kategorier med lavest mulige fejlprocent. I 2012 gik fejlprocenten fra 26% til 15% med AlexNet, hvilket var et gennembrud på daværende tidspunkt. I dag er fejlprocenten for ImageNet konkurrencen nede på 3,1% med netværket GoogLeNet-Inceptionv4 fra 2016, hvilket er bedre end mennesker.
Convolutional Neural Network i dag og i fremtiden
CNN er den oftest benyttede teknologi inden for Computer Vision og billedgenkendelse. I dag bliver teknologien brugt til at løse opgaver som automatisere kørsel og diagnosticere sygdomme, men teknologien har potentiale til at løse alle opgaver relateret til at genkende mønstre i billeder. Udviklingen inden for CNN og machine learning er i dag nået rigtig langt. I dag er udviklingen stagneret en smule og hvis teknologien skal blive bedre skal man udvikle helt nye teknikker til at simplificere de nuværende netværker uden at gå på kompromis med resultatet.
En grundpræmis for statistiske modeller er, at vi ikke kan garantere, at de ikke tager fejl. Derfor er der nogle etiske spørgsmål omkring brugen af kunstig intelligens på områder hvor fejl kan betyde dødsfald. Selv hvis algoritmen statistisk set er bedre til at træffe beslutninger end mennesket, så kan de fejl algoritmen begår være anderledes og fuldstændig uforståelige og uigennemsigtige. Så spørgsmålet er om vi vil have en maskine der laver færre fejl end et menneske, men når den laver fejl kan vi ikke forklare hvorfor den laver fejl eller om vi vil have et menneske som laver flere fejl, men kan redegøre for de fejl der laves?
Kilder
- Boureau Y-Lan, Jean Ponce & Yann LeCun: A Theoretical Analysis of Feature Pooling in Visual Recognition. ICML’10 Proceedings of the 27th International Conference on International Conference on Machine Learning, 24.6.2010. Internetadresse: https://www.di.ens.fr/willow/pdfs/icml2010b.pdf
- Fukushima Kunihiko: Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 01.04.1980. Internetadresse: https://www.rctn.org/bruno/public/papers/Fukushima1980.pdf
- Goodfellow Ian, Yoshua Bengio & Aaron Courville: Deep learning. Kapitel 6, side 180 – 187. 1. udg. MIT Press, 2016. Internetadresse: http://www.deeplearningbook.org
- He Kaiming, Xiangyu Zhang, Shaoqing Ren & Jian Sun: Deep Residual Learning for Image Recognition. Microsoft Research, 10.12.2005. Internetadresse: https://arxiv.org/pdf/1512.03385.pdf
- Hubel D.H. & T.N. Wiese: “Receptive fields, binocular interaction, and functional architecture in the cat’s visual cortex” Journal of Physiology (London), vol. 160, 31.7.1961. Internetadresse: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1359523/pdf/jphysiol01247-0121.pdf
- Krizhevsky Alex, Ilya Sutskever & Geoffrey E. Hinton: ImageNet Classification with Deep Convolutional Neural Networks. University of Toronto, 06.12.2012.
- LeCun Leon Bottou, Yoshua Bengio & Patrick Haffner.: Gradient-Based Learning Applied to Document Recognition. IEEE, 01.10.1998. Internetadresse: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf


