

Hvad er NoSQL?
Begrebet NoSQL betegner databaser som ikke er relationelle. Men hvad er en relationel database? En relationel database er organiseret i én eller flere tabeller med rækker og kolonner, hvor dataværdierne er indsat i felterne på hver række. I en relationel database er flere tabeller forbundet med hinanden og deres relation udgør strukturen for denne slags database. Relationelle databaser er den mest hyppigt benyttede type af databaser, og kan manipuleres med ved hjælp af programmeringssproget SQL.
Nedenstående er et eksempel på en tabel i en relationel database:
| id | Navn | Producent |
|---|---|---|
| 1 | Intenso | Kimbo |
| 2 | Gold | Kimbo |
| 3 | Aroma Espresso | Vendia Kaffe |
| 4 | Gran Gusto | Café Noir |
En NoSQL database har ikke nogle relationer eller tabeller. I stedet opbevares dataen på en anderledes måde. Begrebet NoSQL dækker over flere typer af databaser, som hver især specialiserer sig i at håndtere en bestemt slags data, i modsætning til relationelle databaser som kun dækker over den type af databaser som er opbygget med tabeller og relationer.
Dataen i en relationel database er ofte fordelt over flere tabeller og disse tabeller kan ofte kun håndtere data som er struktureret (struktureret data er data som er navngivet og opdelt i grupper, så man hurtigt kan gennemskue hvilken betydning dataen har). I NoSQL databaser er det tilladt at placere alt sin data i én enkel datastruktur. Derudover er NoSQL mere fleksibelt, eftersom det i en højere grad kan indeholde data i flere forskellige former og størrelser – både struktureret, semi-struktureret og ustruktureret data.
Historien bag NoSQL
NoSQL databaser har eksisteret lige siden 1960’erne, men begrebet blev først introduceret til verden i 1998 af Carlo Strozzi. I takt med at det hele tiden blev billigere at oplagre større databaser med flere forskellige datatyper i 2000’erne og 2010’erne begyndte NoSQL databaser at stige i popularitet.
Eftersom der er en grænse for mængden og variationen af data som en relationel database kan opbevare begyndte mange at skifte over til NoSQL. NoSQL databaser er nemlig bedre til at opbevare større mængder af data og det er bl.a. derfor at big data ofte opbevares i NoSQL databaser.
I dag findes der mange databasesystemer der tilbyder at lave NoSQL databaser, heriblandt MongoDB, Cassandra, Couchbase, DynamoDB og Gremlin.
Typer af databaser i NoSQL
Der findes flere måder at klassificere de forskellige typer af databaser i NoSQL med forskellige kategorier og underkategorier, som i nogle tilfælde kan have forskellige navne for samme slags databaser. Derfor er det svært at lave en definitiv liste over alle typerne.
Nedenstående er en liste over nogle af de mest grundlæggende og hyppigst benyttede databaser i NoSQL:
- Dokument-databaser
- Kolonne-databaser
- Nøgleværdi-databaser
- Graf-databaser
- Tidsstempel-databaser
- Objekt-databaser
Disse databaser vil blive gennemgået her.
Dokument-databaser
Dokument-databaser er organiseret, så hver enhed i databasen er et dokument. Dokumentet kan bestå af en masse forskellige varianter af data, bl.a. lister og nøgle/værdi-par. Enhedens data er ofte skrevet i filformaterne JSON, XML, YAML eller bare som helt normal tekst. Fordi at hver enhed i databasen kan indholde så mange forskellige varianter på samme tid, så kan en enkel enhed opbevare data som normalt ville kræve flere forskellige tabeller i en relationel database.
Derudover kan dataen i en enhed både indholde ustruktureret, semi-struktureret og struktureret data, hvilket gør at databasen bliver mere fleksibel og mere i stand til at holde flere forskellige varianter af data. Hver enhed kan tilgås med en unik dokumentnøgle, som ofte er et nummer.
| Nøgle | Dokument |
|---|---|
| 105 | { "Fornavn": "Magnus", "Efternavn": "Thomsen", "Alder": 27, "Døbt": true "Kone": null } |
| 106 | ["Banan", "Æble", 3, false, null] |
I ovenstående eksempel er der angivet dokumentnøglen 105 med et dokument som indeholder et nøgle/værdi-par og dokumentnøglen 106 med et dokument som indholder en liste.
Kolonne-databaser
Kolonne-databaser læner sig meget op af relationelle databaser, da datastrukturen også er delt op i kolonner og rækker. Alle databasens kolonner er delt op i grupper som kaldes kolonne-familier. Hver kolonne-familie indeholder data som er logisk relateret til hinanden. Hver enkel kolonne i en kolonne-familie kan tilgås med et unikt id som ofte er nummeret for rækken som kolonnen ligger på. Da alle kolonnernes data i en kolonne-familie ikke behøver at være udfyldt, betyder det, at antallet af rækker er meget fleksibelt. Dette er en fordel når man skal opbevare data i nogle rækker og ikke har data for alle felterne.
I nedenstående eksempel ses en kolonne-familie med hjemmesidekontaktoplysninger:
| ID | Kolonne-familie: hjemmesidekontaktoplysninger |
|---|---|
| 001 | Hjemmesidenavn: metasql.nu email: info@metasql.com tlf. nr.: 12345678 |
| 002 | Hjemmesidenavn: zinfandel-vin.dk email: info@zinfandel.dk |
Her ses det at telefonnummeret for ID 001 ikke er angivet, men fordi det er en kolonne-database, så er det som sagt ikke nødvendigt at angive dataværdier for alle felterne.
En database kan indeholde mere end én kolonne-familie, ligesom den der er vist ovenstående. I nedenstående eksempel ses endnu en kolonne-familie for navnet på hjemmesideejere:
| ID | Kolonne-familie: Hjemmesideejer |
|---|---|
| 001 | Fornavn: Camilla Efternavn: Pedersen |
| 002 | Fornavn: Niels Efternavn: Steensen |
Begge af de ovenstående kolonne-familier hører til den samme database og derfor vil rækkerne med det samme id i hver kolonne-familie omhandle den samme hjemmeside. Det vil sige at for id’et “001” i “Kontaktoplysninger” vil oplysninger om hjemmesidens ejer kunne ses i id’et “001” i “Hjemmesideejer”. På den måde hænger alle kolonne-familierne sammen gennem deres ID-nummer.
Nøgleværdi-databaser
En nøgleværdi-database indeholder værdier, samt nøgler som giver adgang til værdierne. Dette er optimalt hvis dataens værdi er ukendt, så man i stedet kan få adgang til den gennem navnety på værdiens nøgle. Værdien er ofte ulæselig for mennesker, hvilket kan gøre det besværligt at søge efter den. I stedet søger man efter en bestemt nøgle. Nøglens navn kan være alting, så længe at navnet er unik, men oftest er nøglens navn angivet ved hjælp af en hashfunktion, som fordeler navnene ligelidt for at undgå kollisioner.
| Nøgle | Værdi |
|---|---|
| N1 | 0101010000101010111010101011101010100010 |
| N2 | 0011110001010110100101011101001010100111 |
| N3 | 0101100001011010101101001001010100110011 |
Ovenstående er et eksempel på tre nøgleværdier, hvor nøglernes værdier har vidt forskellige dataformer, som er ulæselige for mennesker.
Det kan være svært at ændre nøglens værdi i denne form for database, da det oftest kun er muligt at slette og tilføje nøgleværdier. Derfor er det nemmeste at overskrive en nøgleværdi, hvis man vil ændre den.
Graf-databaser
I en graf-database skal man tage højde for to forskellige slags informationer:
- Noder – Repræsenterer dataens enheder
- Grænser – Repræsenterer enhedernes relation til hinanden
Ved hjælp af noder og grænser kan man skabe en grafisk illustration af databasen, som kan se sådan her ud:
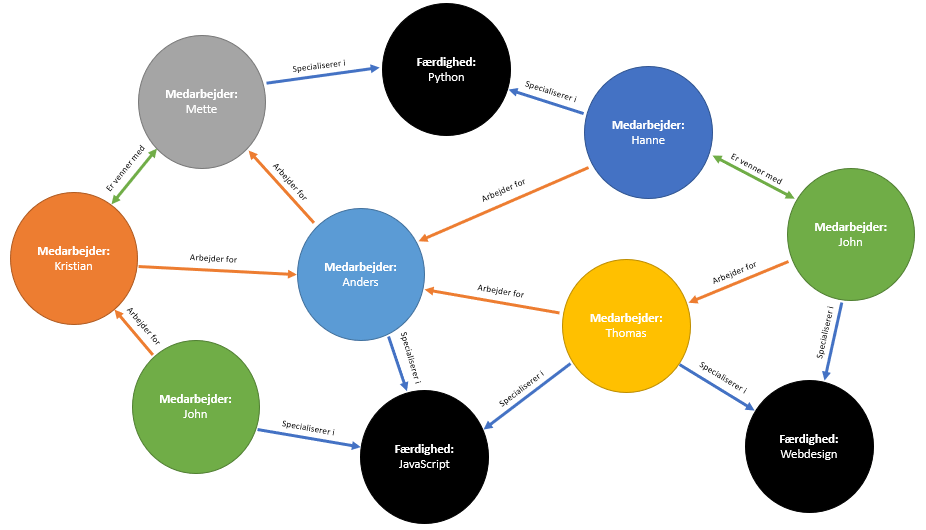
I ovenstående graf vil databasens enheder være cirklerne, hvor der er angivet en medarbejder eller færdighed, og databasens grænser vil være pilene, som viser relationerne for hver enhed og hvilken retning som relationen går i.
Grafen viser de forskellige medarbejdere i en virksomhed og deres forhold til hinanden. Man kan bl.a. se hvem der arbejder for hvem og hvem der besidder hvilke færdigheder.
Fordelene ved en graf-database er, at når man skal finde data i databasen, så kan man søge efter bestemte relationer. I ovenstående graf-database kan man f.eks. søge efter medarbejdere som arbejder for Anders. Det vil give resultaterne: Kristian, Thomas og Hanne.
Tidsstempel-databaser
Tidsstempel-databaser indeholder værdier som er organiseret efter tidspunkt og som tilføjes til databasen i realtid. Oftest er det, at dataværdierne for denne form for database ikke er særlig lange, men til gengæld er der mange af dem og antallet kan stige meget hurtigt lige pludseligt.
| Tidsstempel | ID | Værdi |
|---|---|---|
| 2019-08-04T11:33:05.964 | 001 | 1205 |
| 2020-01-03T03:05:44.732 | 002 | 5392 |
| 2020-03-09T00:58:23.152 | 003 | 2301 |
I ovenstående eksempel er der angivet tidsstempler i første kolonne, som er henholdvis år, måned, dag, time, minut, sekunder og milisekunder. Derefter er der angivet en kolonne med unikke ID’er og til sidst er der angivet en kolonne med selve dataværdien.
Objekt-databaser
Objekt-databaser kan indeholde et stort udvalg af forskellige filformater, som bl.a. kan være billeder, videoer, tekstfiler, og lydklip. En kolonne vil holde informationer om filstien for hver fil. En anden kolonne vil holde et unikt id som bruges til at identificere og finde filen med og en tredje kolonne vil holde metadata som bl.a. kan være hvornår filen er blevet skabt.
| Filsti | ID | Metadata |
|---|---|---|
| python/billeder/filnavn.img | 001 | {created: 2020-04-12} |
| /python/dokumenter/filnavn.cscv | 002 | {created: 2020-04-12} |
| python/dokumenter/filnavn.pdf | 003 | {created: 2020-04-13} |
En objekt-database har ofte meget lagerplads og er specielt god til at holde på store filer.


