Hvad er Lambda arkitektur?
Lambda arkitektur er en bestemt struktur for databearbejdelse, som er designet til at kunne håndtere store mængder data, samt at vise dataen i takt med at det bliver opdateret. Store mængder data bliver også refereret til som big data. Traditionelle databaser, som f.eks. relationelle databaser (data organiseret i tabeller), er ikke i stand til effektivt at opbevare så store mængder data. Der findes nogle NoSQL systemer (systemer som ikke opstiller data i tabeller), som er i stand til at håndtere store mængder data, men disse systemer er ikke særlig alsidige og kræver meget arbejde at vedligeholde. Derfor er lambda arkitektur et simplere og bedre alternativ til håndtering af big data.
De første systemer som blev udviklet til at håndtere big data inkluderer MapReduce fra Google og DynamoDB fra Amazon, men sidenhen har mindre virksomheder også været med til at udvikle innovative datasystemer, som f.eks. Hadoop, MongoDB, HBase, Flink og Cassandra. Disse systemer hører allesammen under NoSQL, og tilbyder hver især nogle unikke fordele. Problemet med dem er, at de ofte er meget komplekse og ikke tager højde for fleksibilitet.
Der er en række egenskaber som man ønsker, når man skal skabe et databasesystem til håndtering af Big data. Disse egenskaber er bl.a. at systemet skal være robust, så det kan håndtere at systemet nogle gange bryder sammen; dataen skal opdatere uden for lange pauser mellem hver opdatering; systemet skal kunne håndtere at modtage både større og mindre mængder data på én gang; systemet skal være alsidigt, så det kan understøtte mange forskellige programmer og former for data; man skal være i stand til at manipulere med dataen; systemet skal være nemt og billigt at vedligeholde, og sidst men ikke mindst, så skal det være muligt og nemt at finde fejl i systemet, hvis der skulle opstå nogle.
Lambda arkitektur er en løsning som indeholder størstedelen af disse egenskaber.
Strukturen for et databasesystem, som er opbygget ved hjælp af Lambda arkitektur, er opdelt i tre lag:
- Batch layer (lag for batch)
- Speed layer (lag for hastighed)
- Serving layer (lag for server)
Funktionen for disse tre lag vil blive gennemgået her.
Batch layer
Batch layer opbevarer et eksemplar af den samlede data ved hjælp af et bearbejdelsessystem som kan håndtere store mængder data. Udover at opbevare dataen så er Batch layer også i stand til at udregne vilkårlige funktioner på datasættet. Batch layer skal være i stand til at opbevare datasættet, hvis størrelse konstant øges i takt med at der kommer ny data. Det nye data kommer ind med jævne mellemrum, så derfor bliver Batch layer hurtigt forældet, da dataen ikke opdateres i realtid.
Speed layer
Ny data modtages af Batch layer i omgange med jævne mellemrum. Det betyder at dataen hurtigt bliver forældet. Derfor sørger Speed layer for at databasen hele tiden bliver opdateret med det nyeste data. Speed layer modtager nemlig også data i takt med at Batch layer gør det. Speed layer bearbejder nemlig dataen i realtid uden det kræver at dataen er komplet. På den måde minimerer laget de mellemrum som opstår ved hver opdatering af data. Ulempen ved at minimere dette mellemrum og vise dataen i realtid er, at ny datamængde kommer ind i mindre partier, hvilket betyder at de ikke altid er nøjagtige.
Serving layer
Serving layer opbevarer dataen fra Batch layer og Speed layer, så det er tilgængeligt at kigge i, samt at foretage kalkulationer og manipulere med. I takt med at batch layer og speed layer modtager et opdateret datasæt, så vil dataen i Serving Layer også blive opdateret. Dette lag præsenterer dataen til de relevante personer og bestemmer om den vil trække dataen fra batch eller speed layer. Den vil foretrække at trække dataen fra batch layer, da dennes data er mere nøjagtig, men hvis man anmoder om helt ny data, så vil den trække det fra speed layer.
Lambda arkitektur modellen
Strømmen af data i en database opbygget ved hjælp af Lambda arkitektur kan ses i nedenstående model:
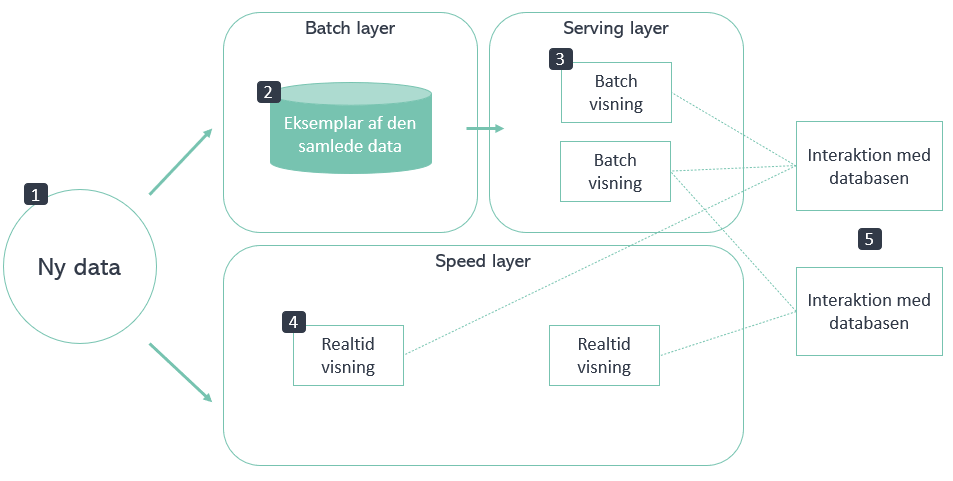
Modellen viser hvordan dataen bliver distribueret i en Lambda arkitektur, samt hvordan databasen integreres med. De forskellige trin er redegjort for her:
- Alt data kommer ind i systemet og bliver fordelt i batch og speed layer
- Batch layer opbevarer et eksemplar af den samlede data og modtager ny data i jævne mellemrum
- Serving layer indekserer dataen fra batch layer, så det kan udtrækkes af databasen
- Speed layer kompenserer for opdateringerne med jævne mellemrum ved konstant at opdatere serving layer med realtidsdata
- Når databasen integreres med vil den blande resultaterne fra batch og speed layer, alt efter hvad der er behov for
Fordele og ulemper ved Lambda arkitektur
De grundlæggende fordele ved at benytte lambda arkitektur er følgende:
- Det er ikke nødvendigt at administrere noget program for at vedligeholde systemet.
- Databasen bliver konstant opdateret med ny data uden lange pauser.
- Systemet er robust og der opstår generelt ikke mange fejl.
- Databasen er fleksibel og skalerbar, hvilket betyder, at den hurtigt og automatisk vil kunne håndtere forskellige mængder af data.
Den største ulempe i forbindelse med lambda arkitektur er, at systemet godt kan være meget komplekst og indeholde store kodestykker, hvilket betyder, at det kan være svært at finde og rette op på fejl i systemet, hvis der skulle opstå nogle.